

MLOps Demystified: the Secret Sauce for Successful Machine Learning




Photo by Sergey Zolkin on Unsplash
MLOps has now become one of the hottest subdomains of Machine Learning. With the rise of Large Language Models (LLMs) and generative AI, the need for Machine Learning infrastructure is greater than ever.
This blog will give an overview of the current state of MLOps and a set of best practices to follow when setting up ML Infra

A Gentle Introduction to MLOps for Beginners!
MLOps, short for Machine Learning Operations, is a set of practices and tools that help organizations effectively manage and deploy machine learning models in real-world applications. It combines the principles of software development and operations with the unique challenges of machine learning.
The purpose of MLOps is to streamline and automate the lifecycle of machine learning models, from development to deployment and maintenance. It aims to ensure that machine-learning projects are reliable, scalable, and reproducible, allowing businesses to derive value from their machine-learning investments.
Traditional software development had well-established practices and tools for managing the software development lifecycle, such as version control systems, continuous integration, and deployment pipelines. However, these practices were not directly applicable to the unique characteristics of machine learning models.
The need for MLOps arose from the specific challenges organizations face when working with machine learning models.
In simpler terms, MLOps helps organizations take their machine learning models out of the research or experimental phase and integrate them into practical use. It provides a systematic approach to building, testing, deploying, and managing machine learning models, just like how software developers build and maintain applications.
Why do companies need MLOps? History of Machine Learning Platform
In the early days every company (especially tech giants) and research labs used to develop their own ML Platforms and tools to fit business needs, these systems were closed source and internal in nature without much community support.
As machine learning started showing promising results and demonstrating its potential for solving real-world problems, businesses began recognizing its value. However, they faced challenges in deploying and managing machine learning models in production environments. This led to the emergence of MLOps as a way to bridge the gap between machine learning research and practical application.
Now it is pretty easy and "affordable" for a small-scale ML team to set up their ML infra using readily available tooling like HuggingFace, MLFlow, Weights & Biases, Amazon SageMaker, etc.

Components of an ML Platform
As an ML system is an inherited form of a software system, all the complexities of a traditional software design are well applied to it., all the rules of traditional software best practices are well applied to it.
Also, an ML system heavily is based on data, so the data engineering challenges come along!
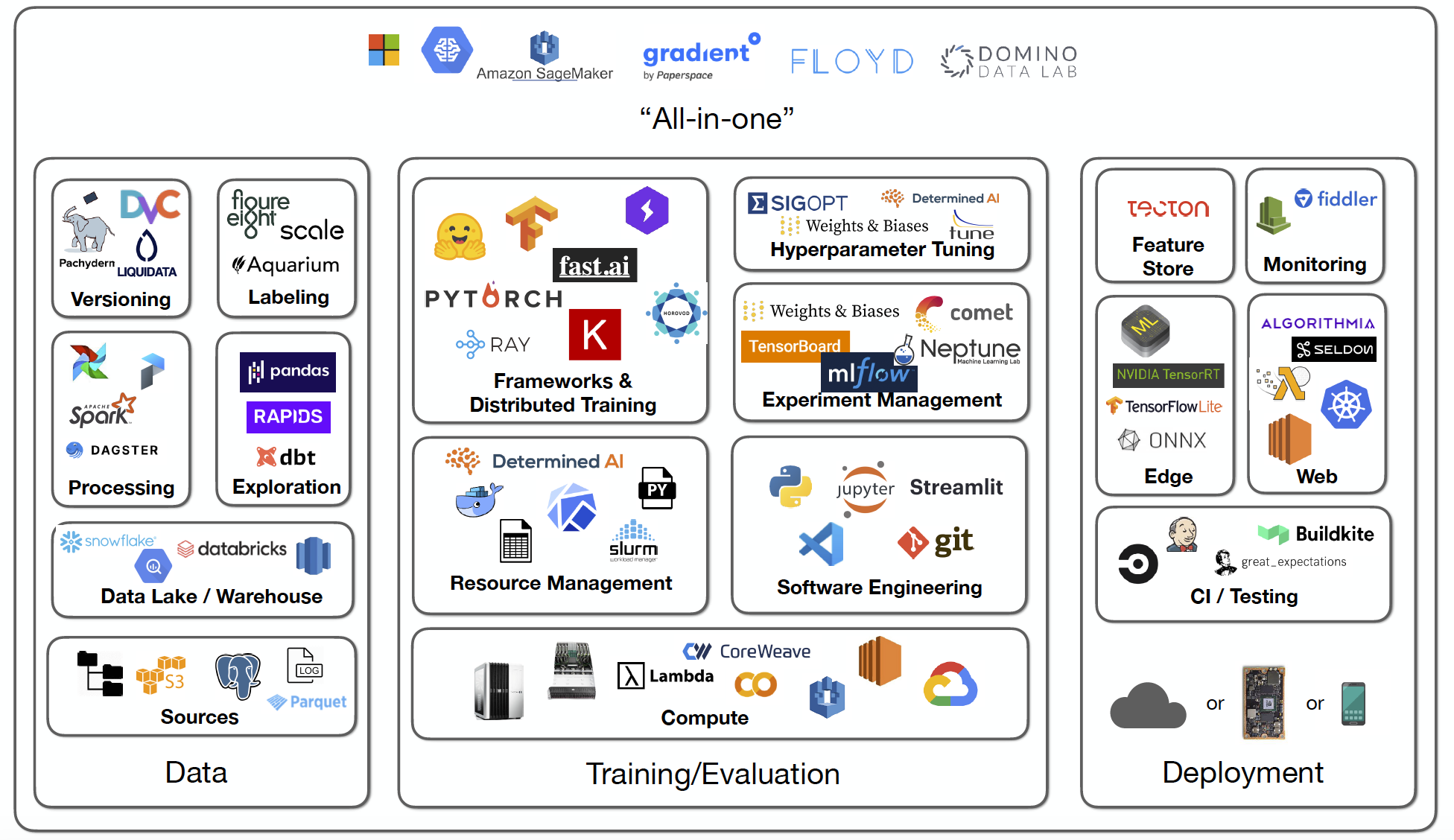
| Component | Description | examples |
| Model registry | Helps to manage the lifecycle of machine learning models. It acts as a central repository for storing, tracking, and governing models at different stages of development and production. Model versioning is supported to keep track of different versions of the same model as it is updated. This allows teams to roll back to previous versions if needed. | MLflow AWS SageMaker |
| ML Pipelines and Orchestration | ML pipelines consist of multiple steps like data collection, preprocessing, model training, evaluation, and deployment. Orchestration tools help automate the execution of these steps in the correct sequence. Orchestration tools improve the efficiency of ML processes by automating repetitive tasks and allowing teams to focus on model development. They make pipelines easier to manage and scale. | Kubeflow SageMaker Pipelines Apache Airflow |
| Feature Store | A centralized repository for features used in machine learning models. It helps manage the full lifecycle of features, from engineering to operationalization. The main purposes of a feature store are to serve as the interface between models and data, manage the full feature lifecycle, and enable collaboration across teams through sharing and reuse of features. | Feast SageMaker Feature Store |
| Experiment Tracking | Experiment tracking tools organize experiments in a central place. This makes it easy to search, compare and analyze experiments. They automate the logging of important metadata for each experiment like hyperparameters, metrics, losses, model weights, hardware consumption, images, audio, video, etc. This makes it easy to reproduce experiments and debug issues. Experiment tracking tools organize experiments in a central place. This makes it easy to search, compare and analyze experiments. They enable collaboration within teams by allowing members to view and comment on each other's experiments. | MLFlow CometML Weights & Biases |
| Model Serving / Inference | ML model serving tools provide a platform for deploying machine learning models into production and serving predictions from those models. They package models in a standardized format so they can be deployed and served. This includes model dependencies, metadata, etc. They provide an API or protocol for clients to make prediction requests to the deployed models. REST and gRPC are commonly used protocols. The main goal of these tools is to bridge the gap between training models in a research environment and reliably serving predictions from those models in production at scale. | SageMaker Endpoints Seldon Core Hugging Face |
| Data Version Control | Data version control refers to the process of tracking changes to data and machine learning models in a version control system, similar to how code changes are tracked in Git. | HuggingFace Datasets DVC |
| CI/CD | In addition to code, it involves integrating changes to data and models. This includes versioning data, models, and their hyperparameters. It also includes continuous training and deployment of models where models are retrained with new data and redeployed based on triggers. It allows for faster experimentation, deployment, and iteration in machine learning projects by automating repetitive tasks. | Argo GitHub Actions Jenkins |
Essential Tips and Tricks for starting your MLOps Journey
MLOps is a growing field with rapid development in tooling. It is easy for an individual to get lost while learning about the ecosystem. I recommend learning the fundamentals of Machine Learning and ML systems first rather than learning a tool. A book that helped me to understand the basics of ML systems is Designing Machine Learning Systems by Chip Huyen
Another great resource for end-to-end learning is Machine Learning Engineering for Production (MLOps) Specialization from DeepLearning.AI
Once you are familiar with fundamentals you will have a good intuition about the tooling. It would be easy for you to navigate and pick the right solution for your needs and not get lost in the ocean of tools.
Most tools started as a single offering and now they are transitioning into an entire platform, a good thumb rule while designing an ML platform is to keep it dead simple and minimal, after all the platform is meant to make the developer effort painless.
I also recommend learning from the Tech Giants about their ML Platform design, as they have put a lot of thought and experience into perfecting their platforms. I personally like Michelangelo from Uber.
Lastly, read more and more about the available tools, try contributing to their open-source codebase, be a part of the MLOps Community, read about the latest developments, and stay in touch with industry experts.