



Table of contents
- Overview of Neural Networks
- What is Sequential Data and Sequence Modelling
- Problems with simple ANNs on Sequential Data
- Design Criteria for RNNs
- Simple RNN Cell
- Traning of RNN cells: Backpropagation through time (BPTT)
- Potential problems with simple RNN units
- Concept of “Gates”
- Drawbacks of RNNs and What's next?
- Summary
Overview of Neural Networks
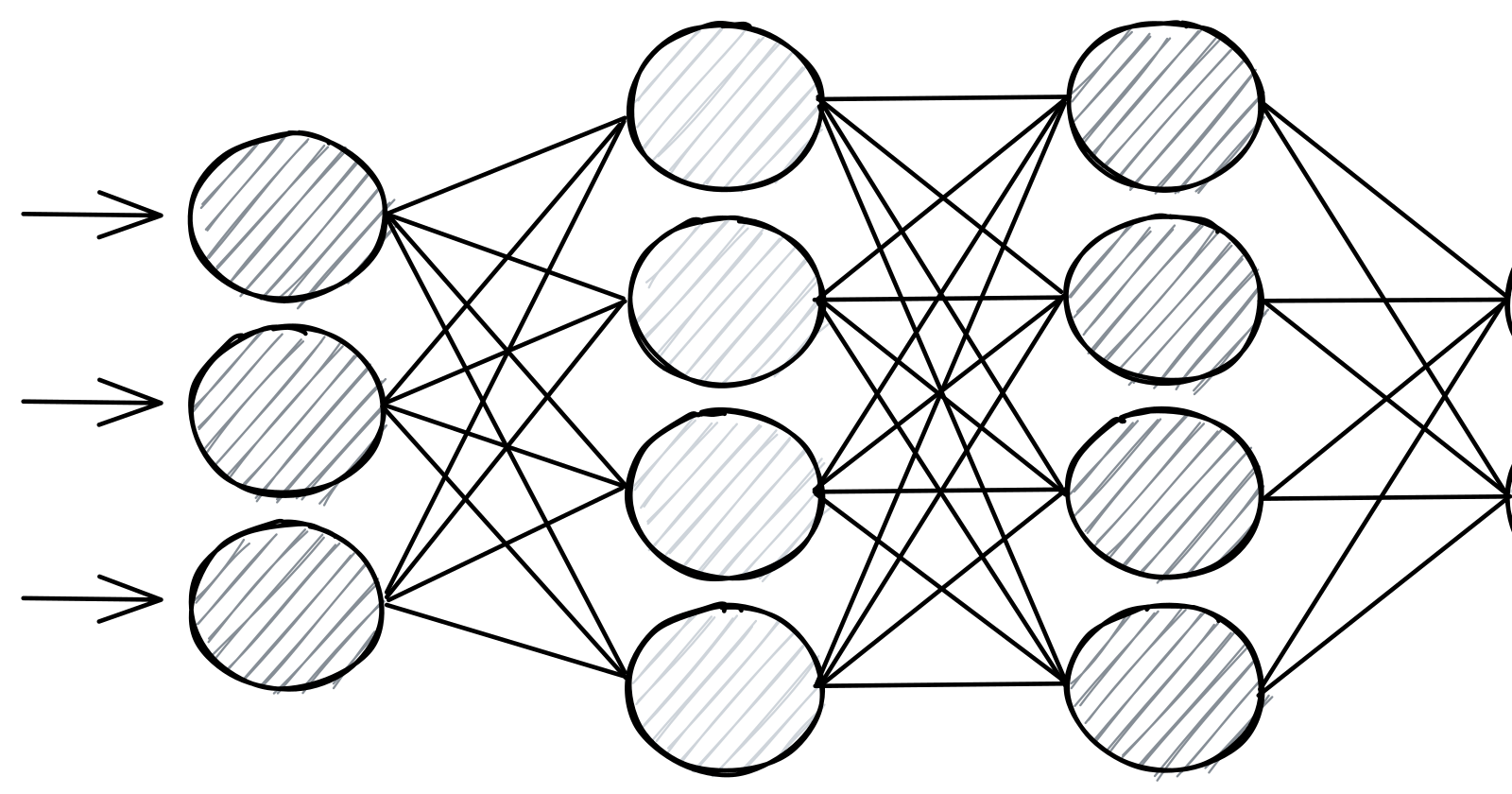
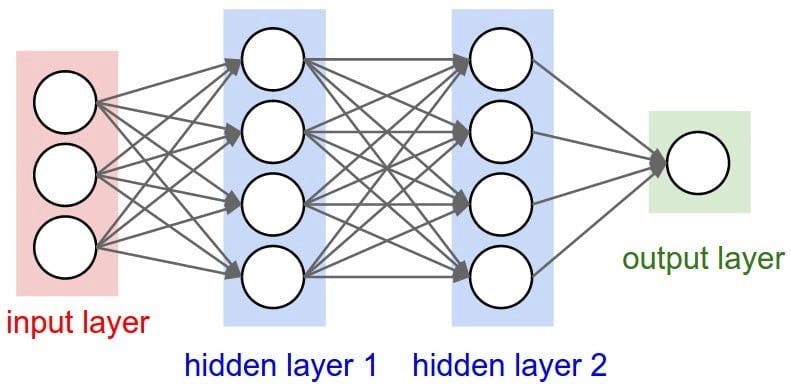
Neural Networks also known as Artificial neural networks (ANN) are a subset of Machine Learning and are at the heart of deep learning. Their structure and names come from the biological neurons inspired by the human brain.
At the very core, Neural Networks are one-to-one mapping of the input data (usually a vector) to another 1-D or multidimensional vector. They comprise a set of interconnected layers mainly containing an input layer, one or more hidden layers, and an output layer. Each layer is a set of one or many artificial neurons that have a weight and bias as parameters.
Each layer is represented with a Matrix [m*n] where m is the size of the layer and n is the size of the previous layer. Input data is passed to the input layer and multiplied with the matrix. The resulting matrix is passed to the next layer and so on. The last layer spits out the output vector that can be used as an inference result.
What is Sequential Data and Sequence Modelling
- Sequential Data
- Sequential data refers to any type of data where information is arranged in a particular order. Time is a component of the data. Examples include Textual data, time series data, DNA sequences, Sequences of user actions, etc.

- Sequence Modelling
- Sequence modelling can be described as the process of producing a sequence of values from an input of sequential data. In other words, neural networks are used to capture the relationship between sequential input and output data. When sequence modelling is applied to natural language data they are called language models.
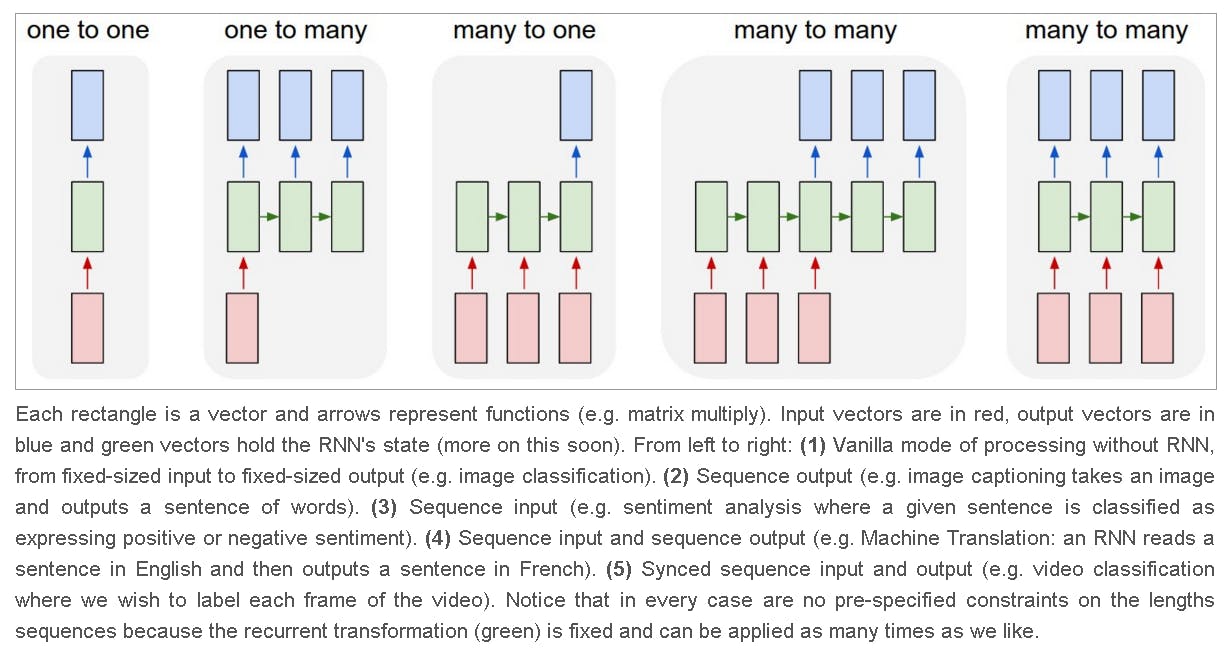
Types of sequence modelling
One-to-one
This is the vanilla mode of processing with fixed-sized input and output. Each input is just mapped to one output. Example Image classification
Many to one
The input contains a sequence of data, but the output contains a fixed length of data. Example sentiment classification where the input can be a sentence with variable number of words but the output is always a single scaler value of positive or negative.
One to many
The input contains a fixed-sized input but the output contains variable-length sequential data. An example is Image captioning where the input is an image but the output is a sequence of text describing the image.
Many to Many
Here both the input and output are variable length sequential data. Examples include Neural Machine translation that powers Google Translate
Problems with simple ANNs on Sequential Data
Definition/ Example
- Can only handle fixed input length: The input and output size of an Artificial Neural Net model is pre-defined, so it becomes super difficult to map variable length input and output. One can argue that model can be used multiple times for each element of input and output, but that would preserve any information related to sequence or order.
Cannot preserve the order of information (sequence): It is perplexing to extract information from the sequence or the order in which the elements are present in the data. Essentially for sequential data, its order is a piece of critical information.
For example, the sentence “Mom is in the kitchen cooking chicken” has a completely different meaning from “Mom is in the chicken cooking kitchen” or “Chicken is in mom kitchen cooking”. The order of words completely changes the here for textual information. Similar is the case with other forms of sequential data.
Cannot track dependency information across the sequence: The information that is present early in the sequence can be linked to a piece of information later in the sequence. For example in the sentence “I grew up in France, I am fluent in French” there is an interdependence between the words “France” and “French”, and such connections should be captured by the model. If such information is tracked across the sequence the model can predict the next element in the sequence with better confidence.
This problem becomes challenging with Vanilla ANNs.
Design Criteria for RNNs
- Handle variable-length sequences
- Track long-term dependencies
- Maintain information about the order
- Share parameters across the sequence
To overcome all the above problems, the data is fed along with additional information on the internal state. This way the information about the order is preserved and parameters are shared across the sequence. This clever trick is the key to Recurrent Neural Networks.
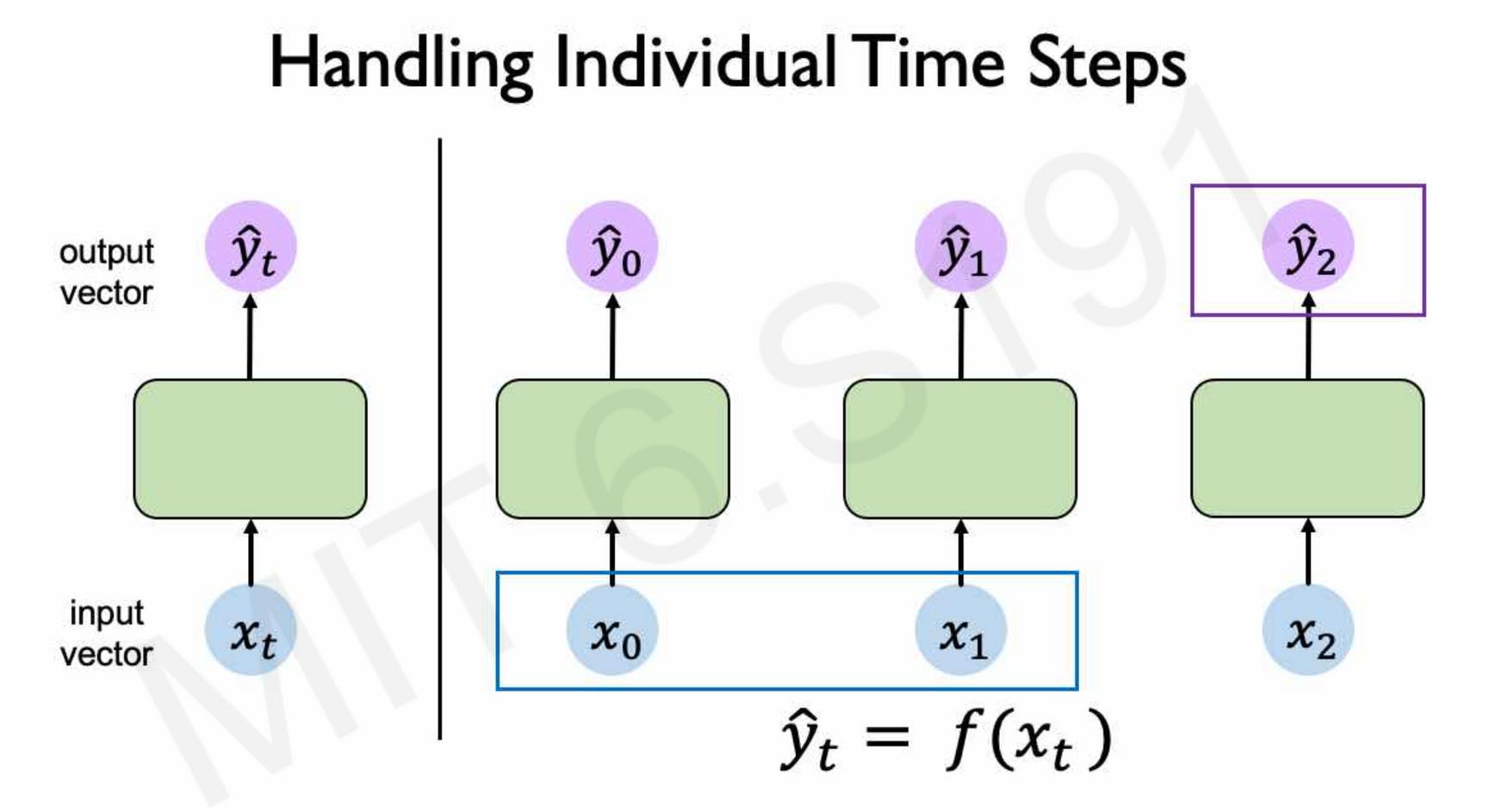
For each element in the sequence of length \( n \) , \( x_n \) is the input and \( y_n \) is the output. Each element \( y_n \) of the output sequence is mapped by the formula \( y_t = f(x_t) \) , and there is no flow of information from the previous element to the next element.
A better way to approach this problem is by introducing a hidden state that is passed to the next element along with the input. Let’s call this hidden state as \( h_t \) \( \) . Now the formula becomes
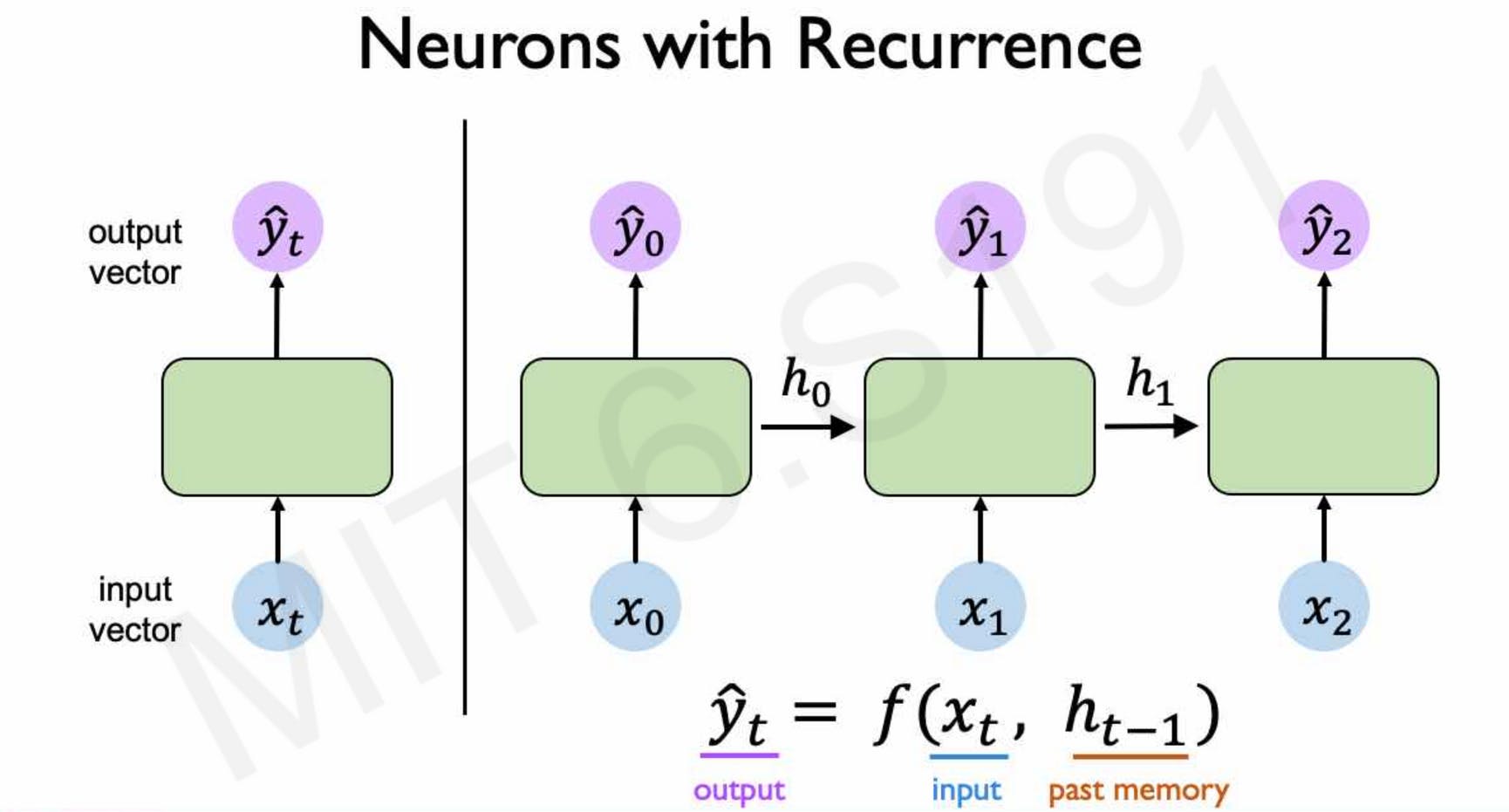
So now we have a flow of information from the previous elements to later elements the later elements of the sequence we have addressed all the conditions of the design criteria.
Simple RNN Cell
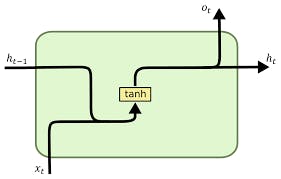
The cell now has one additional input and output ie hidden state from the previous element of the sequence. This hidden state is combined with the current element’s input and passed through an activation function like tanh.
Traning of RNN cells: Backpropagation through time (BPTT)
Simple Backprop algorithm:
- Take the derivative (gradient) of the loss with respect to each parameter
- Shift the parameters in order to minimize the loss
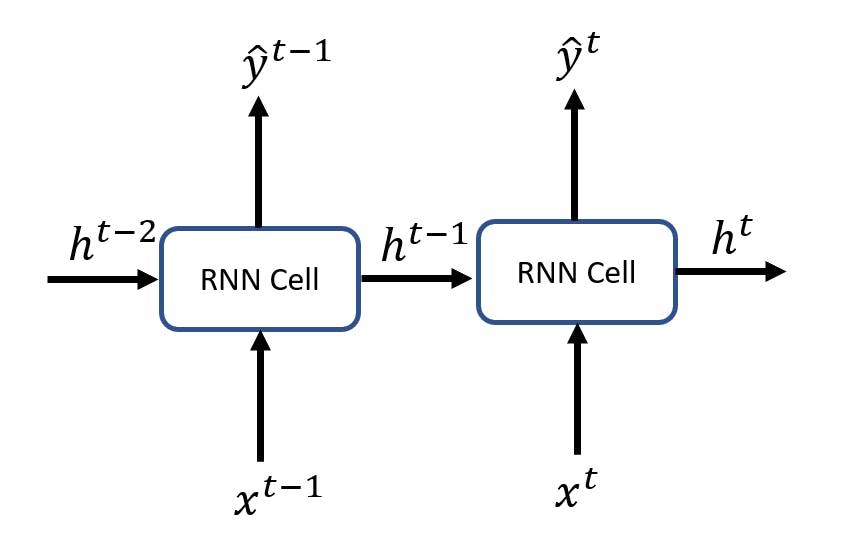
Since time is one more component of the sequential data that represents an order of the information, the backprop algorithm has to be applied sequentially in reverse order to tweak the parameters.
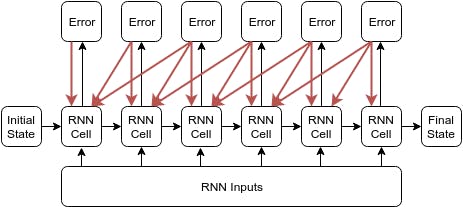
In the diagram, the black arrows represent the forward pass, and the red arrows represent the backward pass. The error is the loss that is computed against a loss function and is used to tweak the value of the parameters (weights and biases). The parameters of the cell are tweaked multiple times for each element present in the sequence.
Potential problems with simple RNN units
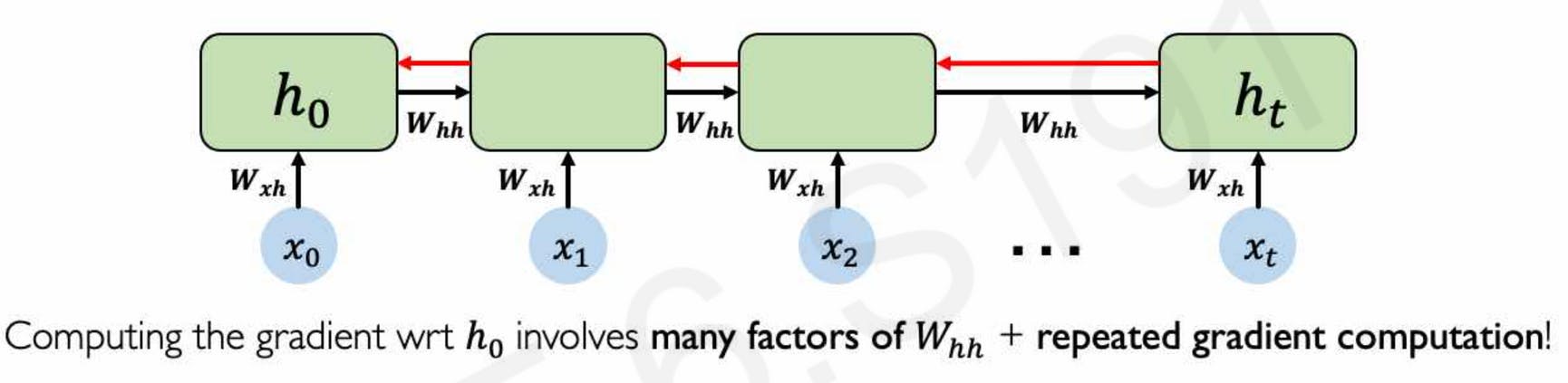
As we saw that RNN cells are needed to be trained using Backprop through time algorithm, which requires the calculation of gradients again and again done by chain derivative. For very long sequences the value of gradients might vanish or explode if it's not near 1. These problems are called the Vanishing Gradients and Exploding Gradients problems.
Multiply many small numbers together → Errors due to further back time steps have smaller and smaller gradients
This results in the failure of the model to capture long-term dependencies, similar is the case when many large numbers are multiplied, and the value of the gradients explodes resulting in exploding gradient problem.
Concept of “Gates”
Why do Gated cells bring to the table?
Adding gates within the cell is a way to control the flow of hidden state information, thus selectively adding or removing information within each recurrent unit.
This simple trick helps the training of RNN cells without interrupting gradient flow and avoids vanishing and exploding gradient problems.
Designing an LSTM cell
LSTM stands for long short-term memory, and it is designed to maintain a memory \( ct \) and a time \( t \) . This set of information is passed to the next cell, and weights are trained against them to have a gated flow.
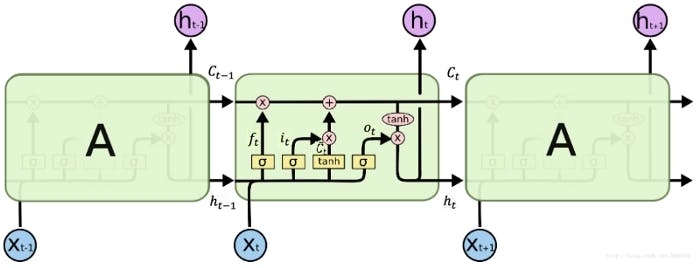
Forget Gate
- The amount to which a cell’s memory is forgotten is controlled by the forget gate.
- \( \sigma \) is a logistical sigmoid function. Uf and Wf are the weights to be learned.
- The forget gate is controlled based on the input \( xt \) from the previous hidden state \( h_t -1 \)
Input gate
- The degree to which new memory is added to the cell memory is controlled by the input gate. -
- Cell State
- Cell state refers to the cell information or memory that is transferred from the previous cell state. The cell memory is obtained by partially forgetting existing memory and adding a new memory component \( C'_t \)
- Output Gate
- The output gate modulated the exposure of the memory content. This is also the amount of memory that is flown from the current cell to the next state.
- The output \( h_t \) or the activation of the LSTM unit is \( h_t = tanh(C_t) * o_t \)
Drawbacks of RNNs and What's next?
- Encoding bottleneck - Since new information is squeezed into the state of an RNN cell and new information is passed to the next cell. This becomes a bottleneck because it's hard to encode too much information into the cell state, and some amount of information is lost during this process.
- Slow, no parallelization - The way inference is computed from the LSTM is synchronous, because of its nature of being sequential. There is no scope of parallelization because the input to the cell is dependent on the output of the previous cell :(
- Not long memory - It's hard to compress information of very long sequences of data, and information is lost every pass. Hence this method is not scalable for long sequences of data.
Attention is all you need To deal with the problems that occurred in the earlier RNN-based architectures, a new concept of Attention mechanism was introduced. Instead of looking at a part of the sequential data, now the model looks at and extracts information from the whole input sequence. The information is extracted into a weighted sum of all the past encoder states.
This allows attaches a weight to a certain element in the sequence, and allows the decoder to asses the elements as well as the weights associated with them. The decoder then produces the output from this encoded state.
Here’s the paper that explores this mechanism in detail %[arxiv.org/abs/1706.03762]
Summary
Recurrent neural networks have been quite influential in the deep learning space. They have produced state-of-the-art results and powered some of the best AI services from Google Translate to Apple’s Siri. It’s the first algorithm with internal memory to preserve cell state and thus make itself perfect for sequence modelling.
However, there is one flaw with RNNs. They have trouble learning the long-term dependencies, hence making them inefficient for very long sequences.
This problem can be addressed to a certain degree by resolving the issue of vanishing gradient problem and exploding gradient problem by introducing a cell state. Using a special type of RNN called LSTM (long short-term memory). But still, it is difficult to scale the model even further. Introducing the attention mechanism can be very helpful to overcome the scale of the input sequence.